画像として与えられた数独を解きます。
新聞に掲載されていたこの問題をOpenCVを使って画像解析する。(画像が斜めなのはワザとです)

グレースケール変換
画像解析の前処理として、まずグレースケールに変換し、ガウシアンフィルタをかけてぼかします。ガウシアンフィルタをかける事で、安定した二値化画像が得られます。

二値化
次に二値化を行います。
二値化には、普通の方法、大津さんの手法、適応的二値化、などさまざまな手法が在ります。いろいろ試した所、適応的二値化(Adaptive Threshold)が最も数独の認識に適していることが解りました。
適応的二値化(Adaptive Threshold)であれば、影になってしまった部分も上手く処理できます。

膨張処理
次に、数独の盤面の外枠を認識を行います。
二値化の影響で枠線が途切れてしまう可能性がありますので、膨張処理(dilate)を行います。
(膨張処理は白色の部分に対して行われるので反転を行なっています。)

大枠の検出
一時的に盤面の大枠以外を取り除きます。
この辺りは非常に泥くさい事をやっていて、失敗する可能性が高いので改善したい所です。

盤面の輪郭を検出します。

矩形の頂点を見つけ出します。
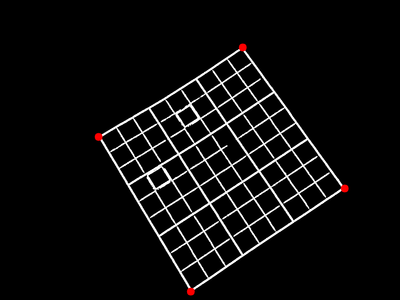
射影変換
先ほど得られた矩形の頂点から、ホモグラフィー行列を求めて射影変換を行います。 これにより、斜めに撮影した盤面を正方形に補正できます。
こちらを参考に実装しました。
膨張処理前の画像に対して射影変換を行うと、こうなります。

ノイズ除去
射影変換を行った画像を単純に9x9分割すると、以下の様にゴミが残ります。
ゴミが残ると、後のOCR処理で誤認するので、取り除かなくてはなりません。
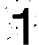
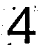
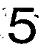
このゴミを除く処理が厄介でした。ラベリングを行いその面積を計算して、認識すべき数字とゴミを区別するのですが、以下の様に枠線が残った場合に数字の「1」や「7」と 区別が付かないという問題がありました。
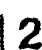
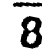

もっと上手く枠線を除去するアルゴリズムを考えたほうが良いかもしれません。
数字を読み取る
OpenCVによる機械学習で数字を分類する事も可能ですが、学習データを集めるのが大変そうなので、Tesseractを使って数字を読み取りました。
現在最新版のTesseract 3.02はなぜか数字の識字精度が悪いのでTesseract 3.01を使うことにした。
問題を解く
テキストになれば、問題を解くのは容易です。こちらのアルゴリズムを実装すれば大抵の問題は解けます。
昔書いた数独ソルバーに問題を渡してやります。
解が得られました。
+---+---+---+
|941|836|257|
|825|179|643|
|736|254|189|
+---+---+---+
|682|395|471|
|197|642|538|
|453|781|962|
+---+---+---+
|568|927|314|
|319|468|725|
|274|513|896|
+---+---+---+
まとめ
- 上記のアイディアを実装して、大体の画像を解けるようになった。
- 正しい認識率は10問中9問程度なのでもう少し精度を上げたい。
- 最初はPythonで書いてたけどPythonのOpenCVバインディング(cv2系)がバグだらけだったので、所々CやC++で書いたコードが混ざってカオスになった。統一したい。
- Tesseract 3.02 の数字の認識精度が悪かった